Области применения онтологий. Задачи, решаемые с помощью онтологий и тезаурусов
3.2. Информационный поиск
Определим базовые понятия в области извлечения документов.
Коллекция - множество документов, имеющих какие-либо общие свойства (например, коллекция документов по заданной тематике или коллекция документов, имеющих только общий формат представления).
Документ - минимальная структурная единица информации, с точки зрения хранения и извлечения из коллекции. Текстовый документ может быть представлен последовательностью более мелких единиц: абзацев, предложений, слов, которые в определенном контексте также являются документами.
При упоминании области информационного поиска - Information Retrieval (IR) - обычно имеют в виду комплексную деятельность по сбору, организации, поиску, извлечению и распространению информации при помощи компьютерных технологий. Теоретическими и инженерными аспектами реализации этих технологий занимаются соответствующие научные и инженерные дисциплины.
Примерами задач в области информационного поиска являются:
- собственно информационный поиск документов по запросу пользователя;
- автоматическая рубрикация документов по заранее заданному рубрикатору;
- автоматическая кластеризация документов - разбиение на кластеры близких по смыслу документов;
- разработка вопросно-ответных систем - поиск точного фрагмента текста, отвечающего на вопрос пользователя, а не целого документа;
- автоматическое составление аннотации документа и многие другие.
Как любая деятельность, IR имеет цель - обеспечить удовлетворение потребности в информации (или информационной потребности) пользователя. Но сама информационная потребность представляет собой некое психологическое состояние человека. Поскольку в настоящее время не существует носителей для такого рода информации, то единственный способ выразить информационную потребность состоит в ее изложении в форме, доступной для обработки машиной - например, в форме запроса, написанного на естественном языке (ЕЯ). Такой способ очень удобен для человека, но может повлечь за собой несколько проблем. Одна из них состоит в том, что запрос может иметь несколько разных толкований (трактовок). Он может быть неполным или избыточным, содержать многозначные слова, сильно зависеть от контекста, плохо отражать информационную потребность и т.п. При этом информационная потребность в каждый момент времени остается постоянной, она не допускает альтернативных или взаимоисключающих трактовок. Хотя запрос редко в точности соответствует информационной потребности, это единственный способ связи между пользователем и поисковой машиной.
Поисковая машина ( поисковик ) использует запрос как входные данные для получения того или иного результата - выборки из коллекции документов, соответствующих запросу (поисковая машина находит документы, релевантные запросу). Здесь возникает вторая проблема: пользователь оценивает результат поиска в соответствии со своей информационной потребностью, а не в соответствии с введенным запросом. В ходе оценки он принимает решение о релевантности (мере соответствия) результата поиска и его (пользователя) информационной потребности. Такую оценку может произвести только сам пользователь. Соответствующее суждение о релевантности и саму релевантность называют истинными. Релевантность, вычисляемая поисковиком на основе его внутренней логики, может не соответствовать истинной релевантности.
Например, пользователя, написавшего запрос "школы бальных танцев России", могут интересовать как различные школы бальных танцев, расположенные на территории России, так и школы в широком смысле этого слова (например, "школа Нуриева"). Пользователь может иметь цель поступить в какую-нибудь школу, узнать, какие педагоги ведут занятия или просто найти партнера по танцам. Все эти намерения скрыты от поисковой машины и не могут быть использованы для вычисления релевантности.
Существуют и другие способы определения релевантности. Например, с учетом полезности: тематическая релевантность и утилитарная релевантность. Данный документ может точно соответствовать информационной потребности пользователя по теме ( тематическая ), но при этом быть совершенно бесполезным для выполнения конкретной деятельности, в рамках которой возникла потребность ( утилитарная ).
С точки зрения пользователя, работа поисковой машины начинается после отправки запроса. Фактически, этому предшествует важный этап индексирования коллекции документов. Он заключается в создании индексных таблиц, значительно ускоряющих обработку запросов. Идея индексирования массивов данных для ускорения доступа применяется повсеместно. Примером индекса может служить алфавитный или предметный указатель в конце книги, оглавление. Даже закладки, сделанные в определенных местах книги, являются своего рода индексом. Индексы широко применяются для ускорения доступа в СУБД. Особенность индексирования в IR состоит в том, что индекс, необходимый для полнотекстового поиска в электронных коллекциях, является наиболее полным. Он должен содержать все термины, которые появляются в документах коллекции. Индекс, который содержит все термины, появляющиеся в документах коллекции, называется обратным (инвертированным) файлом. Часто вместо всевозможных форм каждого слова в инвертированный файл включают только токены - части слов, остающиеся после отсечения окончаний. Например, словам "столы", "столу", "столом" соответствует единственный токен "стол". К числу токенов также относят числа, буквенно-числовые коды, аббревиатуры и т.п.
Для каждого токена на множестве документов вычисляются следующие характеристики:
- число документов, в которых появился данный токен (эта характеристика говорит о распространенности токена в коллекции);
- частота встречаемости токена в коллекции (эта характеристика показывает, насколько данный токен "необычен" по сравнению с другими).
Кроме того, для данной пары "токен - документ (содержащий данный токен)" в инвертированном словаре хранится информация:
- о частоте встречаемости токена в документе;
- о смещении токена от начала документа. Смещение может измеряться в символах или в словах. Эта характеристика часто используется для быстрого извлечения слов контекста и для составления краткого резюме.
Для многих подходов к организации полнотекстового поиска оказывается достаточно инвертированного файла или подобной структуры данных. Но при извлечении релевантных данному запросу документов необходимо определить способ обработки запроса и вычисления значения релевантности для каждой пары "запрос-документ".
Способы обработки запроса
Исторически одним из первых способов обработки запросов был так называемый булевский поиск. В этом подходе слова запроса соединяются между собой логическими связками:  ,
, 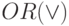 ,
,  . Допустима группировка при помощи скобок. Таким образом, запрос представляется логической формулой, в которой атомами могут быть термины или какие-либо дополнительные условия (ограничение на число любых слов между двумя заданными словами, поиск только в том же параграфе или предложении текста, поиск точной фразы и т.п.). Поисковая машина, основанная на булевом поиске, возвращает документы, для которых формула-запрос принимает истинные значения. Каждому атому формулы сопоставляется множество документов, для которых значение атома истинно. Если атом является термином, то ему сопоставляется множество документов, в которых термин встречается. Затем над множествами выполняются элементарные операции - объединения, пересечения и дополнения, соответствующие логическим связкам между атомами:
. Допустима группировка при помощи скобок. Таким образом, запрос представляется логической формулой, в которой атомами могут быть термины или какие-либо дополнительные условия (ограничение на число любых слов между двумя заданными словами, поиск только в том же параграфе или предложении текста, поиск точной фразы и т.п.). Поисковая машина, основанная на булевом поиске, возвращает документы, для которых формула-запрос принимает истинные значения. Каждому атому формулы сопоставляется множество документов, для которых значение атома истинно. Если атом является термином, то ему сопоставляется множество документов, в которых термин встречается. Затем над множествами выполняются элементарные операции - объединения, пересечения и дополнения, соответствующие логическим связкам между атомами:
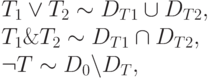
где T, T1 и T2 - атомы, DT - множество документов, для которых атом принимает истинное значение, D0 - множество всех документов коллекции.
Такой подход к обработке запроса имеет ряд недостатков.
- На данный запрос поисковая машина может вернуть очень много документов (или даже все документы коллекции). В этом случае пользователь вынужден последовательно добавлять условия в запрос, чтобы уменьшить результирующую выборку. Поиск производится методом проб и ошибок.
- Как правило, полезную выборку обозримого размера можно получить, задав сложную логическую формулу. При этом от пользователя требуется не только знание правил построения формул, но и достаточно хорошее знакомство с "языком" предметной области.
- Вследствие того, что существует только два значения релевантности: "релевантен" ( true ) и "нерелевантен" ( false ), результирующая выборка не может быть упорядочена по релевантности. Все документы одинаково релевантны.
- Все атомы формулы имеют одинаковую важность (вес), хотя некоторые из них могут быть "ключевыми", другие - вспомогательными.
Существуют способы улучшения качества булевого поиска. Для автоматического расширения запроса синонимичными терминами можно использовать тезаурус или другой ресурс онтологического характера.
Негативные стороны булевого поиска связаны с формализмом обработки запроса. Для их устранения необходимо изменить сам подход. Однако тот факт, что данный подход имеет недостатки, не означает, что от него нужно полностью отказаться. Многие поисковые системы используют булев поиск как альтернативу (обычно под заголовком "Расширенный поиск", что указывает на необходимость дополнительных знаний и навыков пользователя).
Основным способом обработки запросов поисковыми машинами в Интернете является ранжированный поиск. Он основан на вычислении релевантности через распределение частот встречаемости терминов запроса по документам коллекции. На вход может поступать запрос на естественном языке. В процессе предобработки из запроса удаляются стоп-слова (например, "где", "почему" и т.п.) и частицы. Термины сокращаются до токенов. После этого на основе токенов можно было бы автоматически сформировать логическую формулу. Но эксперименты показали, что связывание атомов операцией AND дает слишком мало документов в результирующей выборке и многие релевантные документы остаются за ее пределами (ситуация "выплескивания ребенка вместе с водой"). Связывание атомов формулы операцией OR дает противоположный результат: выборка сильно зашумляется. В данном случае булев подход к обработке естественно-языкового запроса не является адекватным. В этой ситуации дополнительная информация о взаимосвязях терминов (онтология) могла быть использована для формирования более сложной логической формулы.
Вместо того чтобы представлять документы как множества слов, а запрос - как последовательность операций над множествами (как в булевом поиске), предлагается следующее.
Каждый документ коллекции представляется вектором в векторном пространстве, размерность которого равна числу токенов в инвертированном файле. Документ описывается "весами" (координатами) соответствующих токенов. Координатные оси являются попарно ортогональными (токены попарно независимы и образуют базис пространства). Запрос, прошедший предобработку, содержит последовательность токенов и, так же как любой документ, может быть разложен по базису пространства. Далее для вычисления релевантности определяется функция, которая каждой паре векторов ставит в соответствие число из отрезка [0,1]. Крайние точки соответствуют значениям "нерелевантен" и "полностью релевантен". Промежуточные значения определяют степень релевантности документа запросу (или двух документов коллекции, если требуется найти "похожие" документы). Рассмотрим подробнее, как определяются значения весов документов и функция релевантности.
Пусть 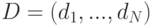 - множество документов коллекции,
- множество документов коллекции, 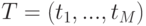 - множество токенов. Для каждого фиксированного
- множество токенов. Для каждого фиксированного  документ
документ 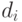 представляется вектором весов
представляется вектором весов
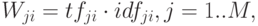
где 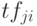 - частота встречаемости токена
- частота встречаемости токена 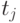 в документе по сравнению с другими токенами документа,
в документе по сравнению с другими токенами документа, 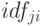 - величина, обратная частоте встречаемости токена по всем документам коллекции.
- величина, обратная частоте встречаемости токена по всем документам коллекции.
На практике часто вместо используется  , где
, где  - число документов в коллекции,
- число документов в коллекции, 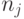 - число документов, в которых встретился .
- число документов, в которых встретился .
Таким образом, документы коллекции представляются векторами с  координатами. Запрос тоже может рассматриваться как документ и представляется вектором
координатами. Запрос тоже может рассматриваться как документ и представляется вектором 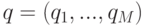 . Матрица
. Матрица 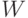 , составленная из векторов документов
, составленная из векторов документов 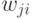 , имеет размерность
, имеет размерность  . Умножая вектор
. Умножая вектор 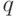 на слева, получим вектор
на слева, получим вектор 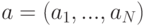 , содержащий значения близости между запросом и всеми документами коллекции. После нормирования
, содержащий значения близости между запросом и всеми документами коллекции. После нормирования  на модуль вектора и вектора
на модуль вектора и вектора  вектор
вектор  будет содержать значения релевантности для каждой пары
будет содержать значения релевантности для каждой пары 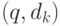 . Иными словами, документы коллекции ранжируются по релевантности данному запросу, что полезно при представлени
и результатов поиска.
. Иными словами, документы коллекции ранжируются по релевантности данному запросу, что полезно при представлени
и результатов поиска.
Еще один подход к обработке запроса основан на вероятностной модели. Это попытка описать ранжированный поиск в терминах теории вероятностей. Проблема состоит в том, что частоты, используемые в ранжированном поиске, по своему смыслу не имеют никакого отношения к вероятностям. Число появлений термина в документе не может служить значением случайной величины и использоваться для оценки вероятности появления данного термина в других документах коллекции. Поэтому частоты встречаемости терминов нельзя применять в стандартных формулах теории вероятностей.
В основу модели положен способ вычисления вероятности того, что данный документ релевантен запросу. В случае, если вероятность достаточно велика, документ считается релевантным.
Основные предположения заключаются в следующем:
- документ
 либо релевантен, либо нерелевантен запросу (т. е. для каждого события
либо релевантен, либо нерелевантен запросу (т. е. для каждого события 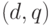 возможно только 2 элементарных исхода
возможно только 2 элементарных исхода 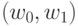 );
); - определение одного документа как релевантного не дает никакой информации о релевантности других документов.
Таким образом, теория не учитывает ни степень релевантности, ни то, что релевантность одного документа может влиять на релевантность других. Этот способ вычисления релевантности далек и от определения истинной релевантности, и от определения полезной релевантности. Однако сами значения вероятности релевантности могут быть полезны при представлении результатов (для упорядочивания выборки).
Вероятность извлечения из коллекции документа 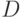 , релевантного запросу
, релевантного запросу 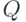 , может быть выражена так:
, может быть выражена так:
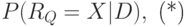
где 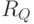 - случайная величина, принимающая значения из множества
- случайная величина, принимающая значения из множества 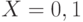 .
. 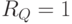 соответствует событию извлечения из коллекции релевантного документа,
соответствует событию извлечения из коллекции релевантного документа, 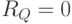 - нерелевантного.
- нерелевантного.
Выражение  для того, чтобы его можно было вычислить, оценивается так:
для того, чтобы его можно было вычислить, оценивается так:
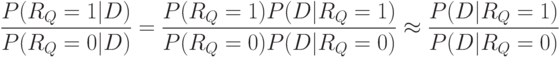
Отношение в левой части равенства ("близость" документа и запроса) показывает, насколько вероятность извлечь из коллекции релевантный запросу документ больше вероятности извлечь нерелевантный документ.
Отношение после знака эквивалентности оценивается с использованием распределения терминов запроса по документам коллекции:

Эксперименты показали, что качество работы поисковых машин на основе вероятностной модели в целом не лучше поисковиков, основанных на ранжированном поиске.
Оценка качества информационного поиска
С ростом числа поисковых машин, различных методик, алгоритмов поиска возникла необходимость сравнивать качество их работы. Для этого были введены две характеристики: точность (  ) поиска и его полнота (
) поиска и его полнота ( 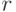 ).
).
Точность (англ. precision, обозн. ) - доля релевантных документов выборки по отношению ко всем документам в выборке.
Полнота (англ. recall, обозн. ) - доля релевантных документов в выборке по отношению ко всем релевантным документам коллекции.
Эти два критерия обычно конфликтуют. Стопроцентная точность и полнота на практике недостижимы.
Пусть - число документов в коллекции,  - число документов в коллекции, релевантных некоторому запросу,
- число документов в коллекции, релевантных некоторому запросу,  - число документов в выборке, полученной системой на данном запросе,
- число документов в выборке, полученной системой на данном запросе,  - число релевантных документов в выборке. Тогда
- число релевантных документов в выборке. Тогда
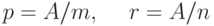

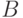
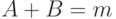
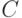
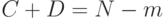
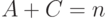

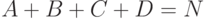
Попытки улучшить качество информационного поиска на основе онтологических ресурсов
Конкретные примеры использования онтологий для приложений информационного поиска в рамках булевской и векторной моделей будут подробно рассмотрены в следующих частях.
- WordNet в сочетании с векторной моделью информационного поиска в экспериментах H. Voorhees и P. Vossen.
- WordNet в булевской модели поиска вопросно-ответной системы Южного Методистского университета США.
- Традиционные информационно-поисковые тезаурусы в комбинации с разного рода статистическими моделями.
- Тезаурус для автоматического индексирования в булевских моделях поиска документов, в задаче автоматической рубрикации, автоматического аннотирования.