




|
не хватает одного параметра: static void Main(string[] args) |
Опубликован: 23.04.2013 | Доступ: свободный | Студентов: 860 / 186 | Длительность: 12:54:00
Лекция 8:
Распараллеливание циклов. Класс Parallel
Короткие и длинные итерации
Рассмотрим цикл, допускающий распараллеливание:
for(int i = 0; i < n; i++) { body }Возникает естественный вопрос, сколько потоков следует создавать для оптимального выполнения этого цикла? Если создавать n потоков, каждый из которых будет выполнять одну итерацию, то время выполнения цикла 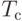 можно представить следующим образом:
можно представить следующим образом:

Здесь  это накладные расходы, связанные с созданием и удалением потоков, а
это накладные расходы, связанные с созданием и удалением потоков, а 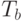 - это максимальное время выполнения одной итерации. Для хорошо сбалансированных итераций можно полагать, что - это время выполнения одной итерации.
- это максимальное время выполнения одной итерации. Для хорошо сбалансированных итераций можно полагать, что - это время выполнения одной итерации.
Накладные расходы зависят от n - длины цикла. Кажется, что для больших значений n накладные расходы могут быть слишком велики. Кажется, что наилучшие результаты могут быть достигнуты, когда n сопоставимо с числом ядер компьютера. Каждая итерация выполняется в отдельном потоке, каждый поток выполняется отдельным ядром процессора. Значит ли это, что на четырехядерном компьютере, на котором я работаю, распараллеливать имеет смысл циклы длиной не более 10? Если это утверждение верно, то как перейти к короткому циклу, когда n велико?
Это нетрудно сделать, используя классический прием разделения длинного цикла на два цикла. Область изменения индекса [0, n-1] разбивается на группы (сегменты) и вначале идет внешний цикл по числу групп, а внутренний цикл идет по элементам группы. По сути это означает применение сегментного алгоритма, описанного в предыдущих главах. Рассмотрим цикл:
for(int i = 0; i < n; i++) { body(i) }Область изменения индекса цикла разобьём на p сегментов. Заменим наш цикл двумя циклами:
int p = 10;
int m = n / p;
int start = 0, finish = 0;
//Внешний цикл распараллеливается
Parallel.For(0, p, (j) =>
{
start = j * m;
finish = (start + m < n) ? start + m : n;
//Внутрений цикл удлиняет итерацию внешнего цикла
for (int i = start; i < finish; i++)
{
body(i);
}
});При замене цикла for циклом Parallel.For возникает естественный вопрос, что лучше иметь ли короткий параллельный цикл и длинные итерации или длинный параллельный цикл с короткими итерациями?
Пример предыдущего раздела, где n было достаточно велико - 10000, - а итерации совсем короткие, показал, что в этой ситуации цикл Parallel.For дает хорошие результаты, и накладные расходы не столь существенны. Это говорит о хорошей реализации инструмента Parallel.For. В то же время непосредственная работа с потоками приводит к большим потерям времени. Накладные расходы в этом случае играют существенную роль. Итерации не должны быть слишком короткими, поскольку в этом случае происходит частое переключение потоков. Следует ли стремиться к длинным итерациям, переходя к коротким циклам?
Давайте рассмотрим противоположную ситуацию, построив для этой же задачи короткий параллельный цикл, увеличив время выполнения одной итерации. Применив вышеописанный прием, разобьем цикл на два цикла, где внешний цикл будет распараллеливаться, а внутренний станет частью body внешнего цикла:
/// <summary>
/// Разбиение на два цикла
/// Применяем Parallel.For к внешнему циклу
/// </summary>
static void Sample6P()
{
int[] temp = new int[n];
int p = 100;
int m = n / p;
int start = 0, finish = 0;
//Внешний цикл распараллеливается
Parallel.For(0, p, (j) =>
{
start = j * m;
finish = (start + m < n) ? start + m : n;
//Внутрений цикл удлиняет итерацию внешнего цикла
for (int i = start; i < finish; i++)
{
x[i] = Fx(i);
temp[i] = Fs(i);
}
});
S = 0;
for (int i = 0; i < n; i++)
S = S + temp[i];
}Как ведет себя Parallel.For в этой ситуации? Вот результаты теста:
Можно видеть, что сокращение длины распараллеливаемого цикла за счет увеличения времени выполнения одной итерации дает отрицательный эффект, увеличивая на порядок время работы. Итог этого исследования следующий - если итерации цикла не являются слишком короткими, то не следует увеличивать длину итерации, разбивая внешний цикл на два цикла и распараллеливая только короткий внешний цикл. Лучшее решение дается для длинного цикла и длинных итераций. Оптимальное решение определяется конкретной задачей.
Продолжим эти исследования на примере классической задачи умножения матриц, где последовательный алгоритм выполняет три цикла, два из которых распараллеливаются естественным образом, благодаря независимости итераций. Третий цикл, вычисляющий скалярное произведение векторов (i-ой строки одной матрицы и j-го столбца другой матрицы), также допускает распараллеливание, поскольку представляет схему суммирования, распараллеливание которой подробно обсуждалось. Вопрос, который нас будет интересовать, какие циклы следует распараллеливать в этой задаче.
Построим простой класс для работы с матрицами. Для наших исследований ограничимся рассмотрением квадратных матриц. Вот общая часть нашего класса:
/// <summary>
/// Работа с квадратными матрицами
/// </summary>
class MultMatr
{
//Размер матриц
int n;
//Квадратные матрицы [n, n]
int[,] A, B, C;
public int dc, dab;
Random rnd = new Random();
public MultMatr(int n)
{
this.n = n;
A = new int[n, n];
B = new int[n, n];
C = new int[n, n];
dc = dab = 0;
}
public void Init_AB()
{
for (int i = 0; i < n; i++)
{
A[i, i] = rnd.Next(1, 10);
B[i, i] = rnd.Next(1, 10);
}
}При инициализации умножаемых матриц ограничимся диагональными матрицами. На времени работы это сказываться не будет, а следить за корректностью умножения проще. Приведу вначале классический последовательный алгоритм:
/// <summary>
/// Классический последовательный
/// алгоритм умножения матриц
/// </summary>
public void MultS()
{
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
C[i, j] = 0;
for (int k = 0; k < n; k++)
C[i, j] += A[i, k] * B[k, j];
}
}Вот версия, где распараллеливается только внешний цикл:
/// <summary>
/// Умножение матриц
/// Распараллеливание внешнего цикла
/// </summary>
public void MultOuterFor()
{
Parallel.For(0, n, (i) =>
{
for (int j = 0; j < n; j++)
{
C[i, j] = 0;
for (int k = 0; k < n; k++)
C[i, j] += A[i, k] * B[k, j];
}
});
}В следующей версии распараллеливаются два цикла:
/// <summary>
/// Умножение матриц
/// Распараллеливание внешнего
/// и внутреннего цикла
/// </summary>
public void MultOuterInnerFor()
{
Parallel.For(0, n, (i) =>
{
Parallel.For(0, n, (j) =>
{
C[i, j] = 0;
for (int k = 0; k < n; k++)
C[i, j] += A[i, k] * B[k, j];
});
});
}Следующая версия позволит проверить следующую гипотезу: что лучше - длинный параллельный цикл или два вложенные параллельные циклы. Ранее мы использовали прием замены длинного цикла, разбив его на группы и представив двумя циклами. Теперь выполним обратное преобразование, заменив два цикла одним:
/// <summary>
/// Умножение матриц
/// Распараллеливание длинного цикла
/// </summary>
public void MultLongCicle()
{
Parallel.For(0, n * n, Mult);
}Мы выполнили свертку двух циклов в один. Метод Mult задает итерацию, выполняемую на каждом шаге цикла. Методу передается параметр цикла и итерации, согласно семантике Parallel.For, могут выполняться в произвольном порядке и параллельно.
Важное замечание
Хочу обратить ваше внимание на причину записи вызова оператора Parallel.For в форме, использующей именованный метод, а не анонимный метод, как это делалось в предыдущих примерах. Сложный анонимный метод, используемый в параллельных вызовах, может приводить к некорректным результатам, а иногда и к возникновению исключительных ситуаций. В данной ситуации необходимо использовать именованный метод. Использование анонимного метода приводит к ошибке. Будьте осторожны, при использовании анонимных методов при распараллеливании.Метод Mult имеет вид:
void Mult(int q)
{
int i = 0, j = 0;
i = q / n; j = q - i * n;
{
C[i, j] = 0;
for (int k = 0; k < n; k++)
C[i, j] += A[i, k] * B[k, j];
}
}Для контроля корректности умножения построим метод Check, учитывающий структуру перемножаемых матриц (исходные матрицы являются диагональными матрицами, таким же будет и результат).
public void Check()
{
dc = dab = 0;
for (int i = 0; i < n; i++)
{
dc += C[i, i];
dab += A[i,i] * B[i, i];
}
}А теперь построим тест, позволяющий выяснить эффективность различных версий умножения матриц:
static void TestMM()
{
MultMatr mm = new MultMatr(n);
mm.Init_AB();
T = MyTimer(mm.MultS);
Console.WriteLine("Последовательный алгоритм умножения матриц");
Console.WriteLine("T =" + T);
mm.Check();
Console.WriteLine("Results: " + mm.dc + " : " + mm.dab);
T = MyTimer(mm.MultOuterFor);
Console.WriteLine("Распараллелен внешний цикл");
Console.WriteLine("T =" + T);
mm.Check();
Console.WriteLine("Results: " + mm.dc + " : " + mm.dab);
T = MyTimer(mm.MultOuterInnerFor);
Console.WriteLine("Распараллелен внешний и внутренний цикл");
Console.WriteLine("T =" + T);
mm.Check();
Console.WriteLine("Results: " + mm.dc + " : " + mm.dab);
T = MyTimer(mm.MultLongCicle);
Console.WriteLine("Распараллелен длинный цикл");
Console.WriteLine("T =" + T);
mm.Check();
Console.WriteLine("Results: " + mm.dc + " : " + mm.dab);
}Метод MyTimer измеряет время работы метода, переданного ему в качестве параметра. Реализация его стандартна:
static long MyTimer(VV par)
{
DateTime start, finish;
start = DateTime.Now;
par();
finish = DateTime.Now;
return(finish - start).Ticks;
}Приведу теперь результаты экспериментов. Начнем с коротких итераций, когда перемножаются матрицы небольшого размера (n = 10):
При таких размерах распараллеливание не имеет особого смысла, поскольку с работой прекрасно справляется и последовательный алгоритм. Но, заметьте, и параллельные версии не приводят к заметным накладным расходам.
Увеличим размер перемножаемых матриц в 10 раз (n = 100), объем вычислений при этом увеличится в 1000 раз. Посмотрим, как это скажется на результатах:
Нетрудно видеть, что компьютер легко справляется с такими вычислениями. Практически время вычислений измеряется миллисекундами, что сравнимо с ошибкой измерения таймера. Но уже в этом случае заметно некоторое превосходство параллельных алгоритмов над последовательным. Какие либо заключения о том, какая из параллельных версий является предпочтительной пока делать рано. Увеличим размер перемножаемых матриц еще в 10 раз (n = 1000). Вот как выглядят результаты:
На моем компьютере с 4-мя ядрами все параллельные версии обеспечивают 4-х кратное ускорение. Лучшие результаты показывает версия, в которой распараллеливается только внешний цикл. Но, заметьте, и другие версии показывают сравнимые результаты. Проведем еще один заключительный эксперимент, увеличив размер матриц до 2000. Время вычислений теперь уже будет измеряться десятками секунд для параллельных версий, а для последовательного алгоритма счет пойдет на минуты. Вот результаты теста:
И здесь параллельные версии показывают 4-х кратное ускорение в сравнении с последовательным алгоритмом. Лучшей является версия с распараллеливанием одного внешнего цикла.
Подводя окончательный итог проводимым исследованиям, можно сказать, что Parallel.For прекрасно справляется с длинными циклами и длинными итерациями, обеспечивая реально возможное ускорение. Накладные расходы на распараллеливание не ощутимы.
Необходимо помнить, что ответственность за корректное применение Parallel.For лежит на программисте, он должен быть уверен, что итерации цикла, к которому применяется распараллеливание, действительно независимы. Второе предупреждение носит технический характер и связано с текущей реализацией анонимных методов. Применять анонимные методы при распараллеливании хотя и можно, но для сложных методов это наверняка приведет к ошибке. Поэтому рекомендуемый способ работы - использовать в Parallel.For именованный метод, задающий тело цикла.
Алексей Рыжков
Никита Белов
|
Выставил оценки курса и заданий, начал писать замечания. После нажатия кнопки "Enter" окно отзыва пропало, открыть его снова не могу. Кнопка "Удалить комментарий" в разделе "Мнения" не работает. Как мне отредактировать недописанный отзыв? |