Опубликован: 25.11.2008 | Доступ: свободный | Студентов: 5863 / 1158 | Оценка: 4.46 / 4.18 | Длительность: 24:42:00
Тема: Базы данных
Специальности: Администратор баз данных
Лекция 5:
Язык SQL. Формирование запросов к базе данных
Оператор выбора SELECT
Язык запросов (Data Query Language) в SQL состоит из единственного оператора SELECT. Этот единственный оператор поиска реализует все операции реляционной алгебры. Как просто, всего один оператор. Однако писать запросы на языке SQL (грамотные запросы) сначала совсем не просто. Надо учиться, так же как надо учиться решать математические задачки или составлять алгоритмы для решения непростых комбинаторных задач. Один и тот же запрос может быть реализован несколькими способами, и, будучи все правильными, они, тем не менее, могут существенно отличаться по времени исполнения, и это особенно важно для больших баз данных.
Синтаксис оператора SELECT имеет следующий вид:
SELECT[ALL|DISTINCT](<Список полей>|*) FROM <Список таблиц> [WHERE <Предикат-условие выборки или соединения>] [GROUP BY <Список полей результата>] [HAVING <Предикат-условие для группы>] [ORDER BY <Список полей, по которым упорядочить вывод>]
Здесь ключевое слово ALL означает, что в результирующий набор строк включаются все строки, удовлетворяющие условиям запроса. Значит, в результирующий набор могут попасть одинаковые строки. И это нарушение принципов теории отношений (в отличие от реляционной алгебры, где по умолчанию предполагается отсутствие дубликатов в каждом результирующем отношении). Ключевое слово DISTINCT означает, что в результирующий набор включаются только различные строки, то есть дубликаты строк результата не включаются в набор.
Символ *. (звездочка) означает, что в результирующий набор включаются все столбцы из исходных таблиц запроса.
В разделе FROM задается перечень исходных отношений (таблиц) запроса.
В разделе WHERE задаются условия отбора строк результата или условия соединения кортежей исходных таблиц, подобно операции условного соединения в реляционной алгебре.
В разделе GROUP BY задается список полей группировки.
В разделе HAVING задаются предикаты-условия, накладываемые на каждую группу.
В части ORDER BY задается список полей упорядочения результата, то есть список полей, который определяет порядок сортировки в результирующем отношении. Например, если первым полем списка будет указана Фамилия, а вторым Номер группы, то в результирующем отношении сначала будут собраны в алфавитном порядке студенты, и если найдутся однофамильцы, то они будут расположены в порядке возрастания номеров групп.
В выражении условий раздела WHERE могут быть использованы следующие предикаты:
- Предикаты сравнения { =, <>, >,<, >=,<= },которые имеют традиционный смысл.
- Предикат Between A and B —принимает значения между A и B. Предикат истинен, когда сравниваемое значение попадает в заданный диапазон, включая границы диапазона. Одновременно в стандарте задан и противоположный предикат Not Between A and B,который истинен тогда, когда сравниваемое значение не попадает в заданный интервал, включая его границы.
- Предикат вхождения в множество IN (множество) истинен тогда, когда сравниваемое значение входит в множество заданных значений. При этом множество значений может быть задано простым перечислением или встроенным подзапросом. Одновременно существует противоположный предикат NOT IN (множество), который истинен тогда, когда сравниваемое значение не входит в заданное множество.
-
Предикаты сравнения с образцом LIKE и NOT LIKE. Предикат LIKE требует задания шаблона, с которым сравнивается заданное значение, предикат истинен, если сравниваемое значение соответствует шаблону, и ложен в противном случае. Предикат NOT LIKE имеет противоположный смысл.
По стандарту в шаблон могут быть включены специальные символы:
- символ подчеркивания ( _ ) — для обозначения любого одиночного символа;
- символ процента ( % ) — для обозначения любой произвольной последовательности символов;
- остальные символы, заданные в шаблоне, обозначают самих себя.
-
Предикат сравнения с неопределенным значением IS NULL. Понятие неопределенного значения было внесено в концепции баз данных позднее. Неопределенное значение интерпретируется в реляционной модели как значение, неизвестное на данный момент времени. Это значение при появлении дополнительной информации в любой момент времени может быть заменено на некоторое конкретное значение. При сравнении неопределенных значений не действуют стандартные правила сравнения: одно неопределенное значение никогда не считается равным другому неопределенному значению. Для выявления равенства значения некоторого атрибута неопределенному применяют специальные стандартные предикаты:
<имя атрибута>IS NULL и <имя атрибута> IS NOT NULL.
Если в данном кортеже (в данной строке) указанный атрибут имеет неопределенное значение, то предикат IS NULL принимает значение "Истина" ( TRUE ), а предикат IS NOT NULL — "Ложь" ( FALSE ), в противном случае предикат IS NULL принимает значение "Ложь", а предикат IS NOT NULL принимает значение "Истина".
Введение Null-значений вызвало необходимость модификации классической двузначной логики и превращения ее в трехзначную. Все логические операции, производимые с неопределенными значениями, подчиняются этой логике в соответствии с заданной таблицей истинности:
- Предикаты существования EXISTS и несуществования NOT EXISTS. Эти предикаты относятся к встроенным подзапросам, и подробнее мы рассмотрим их, когда коснемся вложенных подзапросов.

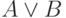
В условиях поиска могут быть использованы все рассмотренные ранее предикаты.
Отложив на время знакомство с группировкой, рассмотрим детально первые три строки оператора SELECT:
- SELECT — ключевое слово, которое сообщает СУБД, что эта команда — запрос. Все запросы начинаются этим словом с последующим пробелом. За ним может следовать способ выборки — с удалением дубликатов ( DISTINCT ) или без удаления ( ALL, подразумевается по умолчанию). Затем следует список перечисленных через запятую столбцов, которые выбираются запросом из таблиц, или символ '*' (звездочка) для выбора всей строки. Любые столбцы, не перечисленные здесь, не будут включены в результирующее отношение, соответствующее выполнению команды. Это, конечно, не значит, что они будут удалены или их информация будет стерта из таблиц, потому что запрос не воздействует на информацию в таблицах — он только показывает данные.
-
FROM — ключевое слово, подобно SELECT, которое должно быть представлено в каждом запросе. Оно сопровождается пробелом и затем именами таблиц, используемых в качестве источника информации. В случае если указано более одного имени таблицы, неявно подразумевается, что над перечисленными таблицами осуществляется операция декартова произведения. Таблицам можно присвоить имена-псевдонимы, что бывает полезно для осуществления операции соединения таблицы с самой собою или для доступа из вложенного подзапроса к текущей записи внешнего запроса (вложенные подзапросы здесь не рассматриваются).
Все последующие разделы оператора SELECT являются необязательными.
Самый простой запрос SELECT без необязательных частей соответствует просто декартову произведению. Например, выражение
SELECT * FROM R1, R2
соответствует декартову произведению таблиц R1 и R2. Выражение
SELECT R1.A, R2.B FROM R1, R2
соответствует проекции декартова произведения двух таблиц на два столбца A из таблицы R1 и B из таблицы R2, при этом дубликаты всех строк сохранены, в отличие от операции проектирования в реляционной алгебре, где при проектировании по умолчанию все дубликаты кортежей уничтожаются.
- WHERE — ключевое слово, за которым следует предикат — условие, налагаемое -на запись в таблице, которому она должна удовлетворять, чтобы попасть в выборку, аналогично операции селекции в реляционной алгебре.
Рассмотрим базу данных, которая моделирует сдачу сессии в некотором учебном заведении. Пусть она состоит из трех отношений R1, R2, R3. Будем считать, что они представлены таблицами R1, R2 и R3 соответственно.
R1 = (ФИО, Дисциплина, Оценка) ; R2 = (ФИО, Группа) ; R3 = (Группы, Дисциплина)
| R1 | ||
|---|---|---|
| ФИО | Дисциплина | Оценка |
| Петров Ф. И. | Базы данных | 5 |
| Сидоров К. А. | Базы данных | 4 |
| Миронов А. В. | Базы данных | 2 |
| Степанова К. Е. | Базы данных | 2 |
| Крылова Т. С. | Базы данных | 5 |
| Сидоров К. А. | Теория информации | 4 |
| Степанова К. Е. | Теория информации | 2 |
| Крылова Т. С. | Теория информации | 5 |
| Миронов А. В. | Теория информации | Null |
| Владимиров В. А. | Базы данных | 5 |
| Трофимов П. А. | Сети и телекоммуникации | 4 |
| Иванова Е. А. | Сети и телекоммуникации | 5 |
| Уткина Н. В. | Сети и телекоммуникации | 5 |
| Владимиров В. А. | Английский язык | 4 |
| Трофимов П. А. | Английский язык | 5 |
| Иванова Е. А. | Английский язык | 3 |
| Петров Ф. И. | Английский язык | 5 |