|
на стр 6, лекции 3, Очевидно "Ck <= модуль(Gk(е))*b(k+1)" (1) - , подскажите что значит "модуль" и почему это очевидно... |
Опубликован: 26.09.2006 | Доступ: свободный | Студентов: 1800 / 485 | Оценка: 4.25 / 4.12 | Длительность: 17:09:00
ISBN: 978-5-9556-0066-6
Специальности: Программист, Математик
Теги:
Лекция 2:
Списки
Некоторые дополнительные операции со связными списками
Конкатенация. Эта операция предназначена для соединения
двух списков в один результирующий. Она эффективна в тех случаях, когда
обеспечен доступ к последнему элементу списка с
трудоемкостью 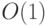 .
При соединении двух списков
.
При соединении двух списков 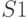 и
и 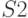 первый элемент
списка становится преемником последнего элемента списка . При этом
возникают вопросы — должен ли получившийся список иметь какое-то новое
имя и должны ли сохраниться как таковые исходные списки
и ?
первый элемент
списка становится преемником последнего элемента списка . При этом
возникают вопросы — должен ли получившийся список иметь какое-то новое
имя и должны ли сохраниться как таковые исходные списки
и ?
В рассмотренной ниже процедуре Concat, реализующей операцию
"Соединить два
списка", принято следующее решение. К списку
присоединяется
список , список сохраняется, а результирующим
является
список . Следует, однако, понимать, что если в список
будут внесены изменения, они автоматически произойдут в новом списке.
Трудоемкость этой операции — .

Из списка  удалить элементы, удовлетворяющие некоторому
условию. Предположим, что требуемое условие на элемент
удалить элементы, удовлетворяющие некоторому
условию. Предположим, что требуемое условие на элемент  проверяется предикатом condition( ).
проверяется предикатом condition( ).

Построить список , состоящий из элементов данного списка , удовлетворяющих некоторому условию. Предположим, что требуемое условие на
элемент проверяется предикатом condition ( ).

Получить список реверсированием списка
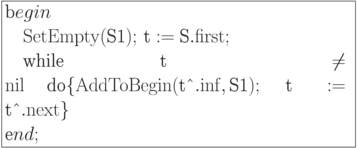
Моделирование списков с последовательным доступом при помощи массивов
Если использование динамических ссылок невозможно или нежелательно (тому
могут быть свои причины), список со связями можно смоделировать при помощи
массивов. В массиве  хранятся элементы списка, то есть
значения соответствующих полей узлов списка со связями. Позицией элемента является
значение целочисленного индекса массива. Кроме того, вводится
целочисленный массив
хранятся элементы списка, то есть
значения соответствующих полей узлов списка со связями. Позицией элемента является
значение целочисленного индекса массива. Кроме того, вводится
целочисленный массив  , в котором для каждого узла списка
указана позиция, где расположен его преемник. В качестве индексного пространства
используем отрезок
, в котором для каждого узла списка
указана позиция, где расположен его преемник. В качестве индексного пространства
используем отрезок ![{[1\ldots n]}](/sites/default/files/tex_cache/f3d3f5f600927300cd4a04e07659d5b8.png) целочисленного типа.
целочисленного типа.
В одних и тех же массивах и
могут размещаться сразу несколько
списков, состоящих из узлов одного типа. С учетом такого возможного
сосуществования различных списков их элементы могут размещаться в этих
массивах хаотично, подобно тому, как узлы списков, представленных
с помощью ссылок, могут произвольно располагаться в памяти компьютера.
На табл. 2.1 показано возможное заполнение массивов и  для одностороннего списка, представляющего кортеж
для одностороннего списка, представляющего кортеж 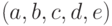 (пустые клетки не имеют отношения к этому списку).
(пустые клетки не имеют отношения к этому списку).
| Адрес | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Inf | e | b | c | d | a | |||||||
| Next | 0 | 6 | 9 | 1 | 3 |
Доступ к списку можно осуществить через его первый элемент, позиция
которого в массиве задается значением переменной 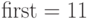 .
Значение
.
Значение ![\Next[1] = 0](/sites/default/files/tex_cache/6559d6146cf326ff1ecc4bb129e61cb5.png) говорит о том, что в позиции
говорит о том, что в позиции 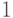 расположен элемент, у которого
нет преемника, то есть последний элемент кортежа.
расположен элемент, у которого
нет преемника, то есть последний элемент кортежа.
На табл. 2.2 показано возможное заполнение
массивов ,  и
и  для представления кортежа (
для представления кортежа ( 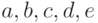 )
двусторонним списком.
)
двусторонним списком.
| Адрес | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| Inf | e | b | c | d | a | |||||||
| Next | 0 | 6 | 9 | 1 | 3 | |||||||
| Precede | 9 | 11 | 3 | 6 | 0 |
Основные отображения 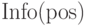 ,
, 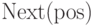 ,
,  ,
,  ,
,  ,
,  задаются очевидным образом. Если какие-либо из них
не заданы явно, то их можно вычислять через другие сканированием списка.
задаются очевидным образом. Если какие-либо из них
не заданы явно, то их можно вычислять через другие сканированием списка.
Чтобы одни и те же массивы  ,
,  ,
,  использовать для одновременного хранения нескольких однотипных списков,
позиции этих массивов объединяют в один так называемый свободный
список
использовать для одновременного хранения нескольких однотипных списков,
позиции этих массивов объединяют в один так называемый свободный
список  .
Это можно сделать, например, с помощью операторов
.
Это можно сделать, например, с помощью операторов
![\formula{
\t begin\\
\mbox{} \q {\rm Avail}.{\rm first} :=1;\ {\rm Next}[\t{n}] := 0;\
\t{for}\ i:= 1\ \t{to}\ \t{n} - 1\ \t{do}\ {\rm Next}[\t{i}]:=
\t{i} + 1;\\
\mbox{} \q {\rm Preced}[1]:= 0;\ \t{for}\ \t{i}:= 2\
\t{to}\ \t{n}\ \t{do}\ {\rm Preced}[i]:= \t{i} - 1;\\
\t{end};
}](/sites/default/files/tex_cache/0f5310d9a74bac639fd7a3ae04e7bcc7.png)
Массив при этом не заполняется. При создании новых
списков используются элементы массивов , , ,
предварительно удаляемые из списка .
В момент создания нового узла из списка
удаляется головной элемент, который и используется для добавления в новый
список. С другой стороны, при удалении элемента из какого-либо списка
освобождаемая позиция добавляется к свободному списку для последующего
использования. Такая техника применялась, когда системы программирования
не имели стандартных средств динамического выделения памяти. Однако
в условиях ограниченной памяти этот прием можно использовать и сейчас. Дело
в том, что при достаточно большом объеме оперативной памяти стандартные
системы вынуждены использовать многоразрядную адресацию, в то время как
для позиционирования в массивах , ,
можно задействовать малоразрядные представления чисел.
Антон Сиротинкин