Lecture
Специфика построения аппаратных платформ высокопроизводительных вычислительных систем с микропрограммным уровнем доступа
Сторонники систолического подхода обычно замалчивают, что проблема состоит не в том, чтобы получить декартово произведение нескольких переменных, а в том, чтобы на регулярной коммутационной структуре добиться " биений " тех и только тех переменных, которые требуется реализовать в конкретном алгоритме. В данном случае речь не идет об учете содержимого данных для снижения количества операций, затрачиваемых на каждый проход алгоритма. Напротив, речь идет о снижении системных издержек на исключение "паразитных" комбинаций внешних и внутренних переменных, которые вносят искажения в реализацию "стягивающих" операторов, у которых выходное значение зависит от произвольного подмножества, заданного на декартовом произведении внешних и/или внутренних переменных.
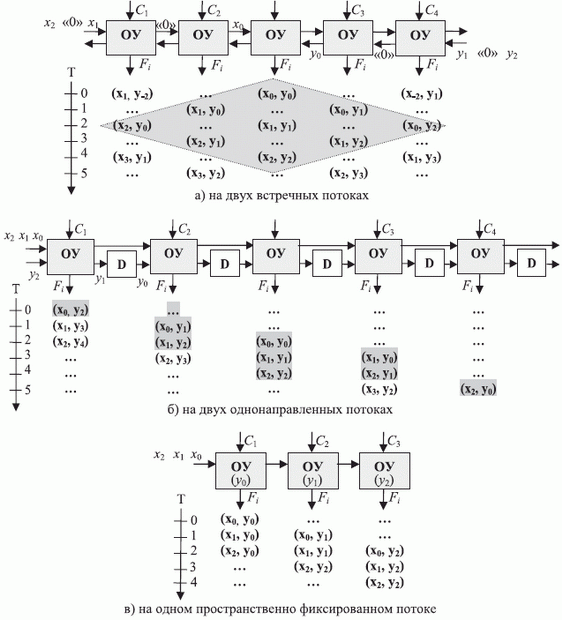
Для реализации "внешней" пространственно-временной коммутации требуется всего три типа линейных (одномерных) систолических структур (рис. 3.7 [289]), в которых декартово произведение реализуется либо на двух встречных потоках, либо на двух однонаправленных потоках, либо на одном распространяемом по линейному конвейеру, а другом предварительно введенном в ОЗУ операционных модулей.
С позиций получения двумерного декартова произведения, определенного на множестве пар индексов обрабатываемых потоков данных, реализуемая операционными модулями арифметико-логическая функция не играет никакой роли, что позволяет на схемах рис. 3.7 абстрагироваться от ее содержания.
Аппаратно-временные характеристики этих схем сведены в табл. 3.4, из данных которой следует:
- Минимальное количество операционных устройств, максимальный коэффициент их использования (без учета времени вхождения в конвейер) и максимальный темп поступления данных приходится на схему рис. 3.7-в.
- При циклическом формировании декартова произведения двух потоков данных
\[
\{x_{i}\}
\]
и
\[
\{y_{i}\}
\]
\[
i,j = \overline{0,N}
\]
в схемах рис. 3.7-а и рис. 3.7-б образуются "паразитные" комбинации за счет встречи
\[
x_{i}
\]
и
\[
y_{i}
\]
, принадлежащих разным циклам обработки. В нашем случае
\[
N = 2
\]
, а значит, комбинации
\[
(x_{2}, y_{3})
\]
или
\[
(x_{3}, y_{2})
\]
и т. п. являются "паразитными". Такие "паразитные" комбинации можно исключить из декартова произведения с помощью многомерной характеристической функции
\[
C_{2k-1}(T) = (c_{1}(T), c_{2}(T), ..., c_{p}(T), ..., c_{2k-1}(T)
\]
). Компоненты этой функции равны "единице" только в те моменты времени
\[
Т
\]
, когда в
\[
р
\]
-ячейке линейной систолической структуры формируются значимые для данного цикла обработки пары переменных
\[
x_{i}
\]
и
\[
y_{j}
\]
. Для этого необходимо селектировать в каждой ячейке линейной систолической структуры весь в данном случае двумерный поток данных с помощью операции
\[
(x_{i}, y_{j}) \land c_{p}(T) c_{p}(T)
\]
, где
\[
\land
\]
- логическое умножение.
Таблица 3.4. Аппаратно-временные характеристики одномерных систолических матриц Схема рис. 3.2 Кол-во ОУ Коэффициент использования Время задержки Объем оборудования Темп обработки а) \[ 2k-1 \] \[ k^2/(2k+1)(2k-1) \] \[ \Delta T_0 k \] \[ 2k-1 \] \[ 2\Delta T_0 \] б) \[ 2k-1 \] \[ k(2k-1) \] \[ \Delta T_0 (k-1) \] \[ \mu_1(2k-1) \] \[ \Delta T_0 \] в) \[ k \] \[ 1 \] \[ \Delta T_0 k \] \[ \mu_2 k \] \[ \Delta T_0 \] - В схеме рис. 3.7-в отсутствуют "паразитные" комбинации \[ (x_{i}, y_{j}) \] , и поэтому селектирующий вектор \[ С_{k}(Т) \] используется только для устранения лишенных физического смысла комбинаций, если таковые имеются в \[ F(x_{i} , y_{j}) \] .
- Наличие селектирующего вектора \[ С \] и маскирующей операции \[ \land \] ("И") говорит о том, что даже простейшие систолические структуры по своей сути являются устройствами ассоциативной обработки [46, 106, 175], правда, в них " DD -ассоциативный вектор" С определяется не с содержимым одной из переменных \[ x_{i} \] или \[ y_{j} \] , а с их индексами \[ i, j \] . Если учесть, что при комплексной обработке информации в (Б)
ВС физически осмысленными являются не все комбинации переменных, то становится очевидным, что маскирование "паразитных" комбинаций является достаточно активной функцией, и такое управление пространственно-временными потоками данных в матричных вычислителях требует дополнительных аппаратных затрат, которые в теоретических исследованиях либо не учитываются, либо замалчиваются.
В дополнение к традиционной для микроэлектроники и вычислительной техники проблеме распределения аппаратно-временных затрат между объектом и средствами управления МКМД-бит-потоковая технология, базирующаяся на принципе "одна инструкция - один процессор", требует решения еще двух центральных для нее проблем:
- организация эффективного взаимодействия распределенного ЗУ произвольной выборки данных и FIFO-регистровой памяти бит-матрицы, первая из которых эффективно реализует хранение и произвольный порядок чтения-записи данных, а вторая эффективно совмещает по времени и аппаратуре передачу и обработку данных в бит-матрице;
- организация эффективного управления системой рассылки и хранения бит-инструкций, в решении которой ЗУ произвольной выборки эффективно реализует не только хранение, но и оперативное управление потоком инструкций в бит-матрице, а FIFO-регистровая память эффективно совмещает по аппаратуре хранение и рассылку бит-инструкций.
Конкретные способы и методы решения этих проблем кардинальным образом влияют на структурно-функциональную схему бит-процессора и на распределение аппаратно-временных затрат между объектом и средствами управления как в МКМД-бит-потоковых СБИС, так и в субпроцессорах на их основе.
Для решения первой из указанных проблем можно все задачи, решаемые современными (Б)ВС, разбить на два класса:
- задачи, решение которых требует арифметико-логического преобразования содержимого обрабатываемых данных, типичным представителем которых является векторно-матричная обработка;
- задачи, решение которых требует арифметико-логического преобразования только индексов обрабатываемых данных, типичным представителем которых являются перестановки типа "транспонирование матриц".
В соответствии с такой классификацией ранжирование данных относится к первому классу, так как перестановки в них осуществляются на основе анализа содержимого ранжируемых данных, как это имеет место при медианной фильтрации сигналов и изображений [290].
Для решения проблем эффективного управления сверхбольшим коллективом МКМД-бит-потоковых вычислителей можно разбить все задачи, решаемые современными (Б)ВС, не на две [273], а на три группы, образующие последовательный тракт обработки и отличающиеся существенно разной динамикой управления:
- предварительная обработка (коррекция, фильтрация и т. п.), которая улучшает качество сигналов и изображений или устраняет всевозможные нелинейные искажения в приемо-передающих трактах и при решении которой, как правило, хватает методов параметрической адаптации алгоритмов;
- первичная обработка, которая направлена на выделение информативных признаков в сигналах и изображениях, что сопряжено с использованием методов структурной и параметрической адаптации алгоритмов;
- вторичная обработка, которая связана с классификацией или распознаванием образов и анализом динамических процессов или сцен, что, как правило, требует методов структурной адаптации алгоритмов.
Первую группу задач можно отнести к сенсорному (периферийному) уровню (Б)ВС. Эти задачи решаются в дежурном режиме и характеризуются достаточно простыми алгоритмами обработки потоков данных, скорость которых уже сейчас достигает сотен Мбит/сек или единиц Гбит/сек. Простой в данном случае считается обработка, требующая десятков арифметико-логических команд, выполняемых практически в "безусловном" (линейном) режиме адресации потоков команд, то есть без ветвлений алгоритма.
Решение задач второй группы происходит в условиях активного противодействия радиоэлектронных средств противника и в плохо прогнозируемых условиях распространения радио-, видео- и ИК-сигналов. Поэтому выделение информативных признаков требует как высокоскоростной обработки потоков данных интенсивностью в сотни Мбит/сек, так и высокой оперативной адаптации под плохо прогнозируемую поме-ховую обстановку, где уже одни методы параметрической адаптации алгоритмов явно недостаточны.
После выделения информативных признаков интенсивность обрабатываемых потоков падает на 1-2 порядка, а большинство задач вторичной обработки естественным образом допускает режим разделения времени: захват цели, сопровождение цели, выбор средств поражения цели и т. п. Существенно, что все эти задачи требуют не только высокой динамики адаптации структур алгоритмов под быстро изменяющиеся рельеф местности, маскирующие факторы и т. п., но и быстрого перехода из одного класса алгоритмов в другой.
Из сказанного следует:
- требования задач первой группы могут удовлетворить программируемые по технологии (П)ПЗУ МКМД-бит-потоковые СБИС, если закладываемые в них алгоритмы и реализуемые на их основе вычислительные структуры допускают модификацию целого ряда параметров, учитывающих хорошо прогнозируемые и измеряемые изменения в работе приемо-передающих трактов (Б)ВС;
- требования задач второй группы могут удовлетворить совместно используемые (П)ПЗУ-программируемые и электрически программируемые МКМД-бит-потоковые СБИС, которые обеспечивают создание высокопроизводительных реконфигурируемых операционных модулей;
- требования задач третьей группы могут удовлетворить большие перепрограммируемые коллективы МКМД-бит-потоковых вычислителей, в которых повышенная активность программной шины снижает массо-габариты и потребляемую мощность субпроцессоров, но требует разработки и использования эффективных методов снижения временных системных издержек от многократного программирования и вхождения в конвейер.
Таким образом, используемая методика нисходящего системного проектирования МКМД-бит-потоковых матричных СБИС направлена:
- на создание проблемно- или алгоритмически ориентированных МКМД-бит-потоковых субпроцессоров с повышенной динамикой управления их программным обеспечением и архитектурой как при решении широкого круга задач управления и боевого применения перспективных ЛА, так и при парировании карт множественных отказов, возникших в результате активного противоборства со стороны технически развитого противника, обладающего оружием направленной энергии;
- на комплексное использование программно и аппаратно совместимых (П)ПЗУ-программируемых и электрически программируемых МКМД-бит-потоковых СБИС с расширенными по отношению к СБИС Н1841 ВФ1 структурно-функциональными возможностями;
- на создание технологии программного конструирования МКМД-бит-потоковых субпроцессоров на основе алгоритмически ориентированных библиотек операционных, адресных, интерфейсных, управляющих и диагностических модулей;
- на создание теоретических и аппаратно-технологических предпосылок для перехода к нейрокомпьютерным технологиям с элементной базой нанометрового или супрамолекулярного диапазона.