Lecture
Специфика построения аппаратных платформ высокопроизводительных вычислительных систем с микропрограммным уровнем доступа
3.2. Особенности методики синтеза ассоциативно управляемых МКМД-бит-потоковых матричных СБИС арифметико-логической обработки данных
Как было показано в разделе 1.6 курса "Задачи и модели вычислительных наноструктур", технология прототипирования требует участия постановщиков задач управления ЛА и его вооружением на самых ранних этапах проектирования (Б)ВС, что в свою очередь требует от них знаний как минимум "системы ценностей" при создании современных средств микроэлектроники и вычислительной техники. Эти знания в первую очередь требуются при выборе вычислительных алгоритмов решения задач.
Так, при оценке эффективности алгоритмов цифровой обработки сигналов и изображений реального времени [273-275] постановщики задач длительное время руководствовались критерием минимума операций умножения. Успехи микроэлектроники конца прошлого столетия привели к тому, что на первое место по временным затратам вышли не арифметические операции деления и умножения, которые в современных RISC -процессорах реализуются аппаратно и с длительностью цикла в один такт, а операции пересылки данных, которые в быстрых алгоритмах цифровой обработки сигналов и изображений реального времени сопровождаются усложнением адресной арифметики. В результате гарантированный теоретический выигрыш в ускорении вычислений резко снижается, и он не окупается ростом аппаратных затрат на векторные адресные сопроцессоры, обеспечивающие поддержку достаточно сложных "сетевых" графов информационного взаимодействия различных программных процедур, закрепленных за разными процессорами параллельных (Б)ВС. Такое положение вещей типично для тех компонент (Б)ВС, от которых требуется не только сверхвысокая производительность, превышающая физические возможности отдельных процессоров, но и повышенная отказоустойчивость в условиях ограниченных массо-габаритов и потребляемой мощности.
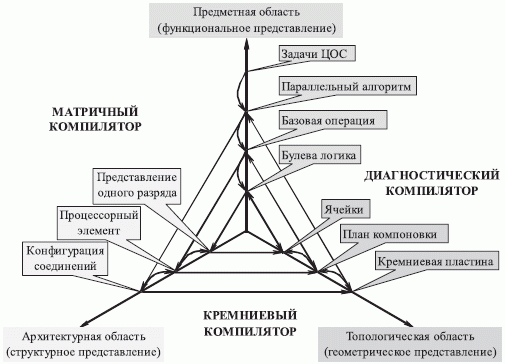
Если абстрагироваться от уровня стандартизации элементной базы, то технология сквозного системного проектирования МКМД-бит-потоковых матричных СБИС требует междисциплинарного подхода к их созданию и содержит те же этапы, что и технология проектирования заказных СБИС для критических задач цифровой обработки сигналов и изображений реального времени [70, 276] (рис. 3.5):
- Выбор базовой задачи, наиболее полно представляющей систему преобразований, используемых при решении класса задач.
- Выбор алгоритма решения базовой задачи с учетом ограничений микроэлектронной реализации.
- Выбор минимального набора операций, достаточного для решения не только базовых, но и всего класса задач с учетом интерфейсных и управляющих функций.
- Выбор алгоритмов базовых операций с учетом ограничений микроэлектронной реализации.
- Выбор структурно-функциональной схемы операционной части бит-процессора (объект адаптации).
- Выбор системы управления бит-процессором. В этом процессе существенное место занимает синтез распределенной системы диагностики и парирования отказов, так как при степени интеграции на кристалле свыше 100 тыс. транзисторов эффективно решить вопросы диагностики после изготовления СБИС практически невозможно, имея доступ только к внешним входам и выходам схемы.
Действительно, в современных процессорах общего назначения, цифровых процессорах обработки сигналов ( ЦПОС ), транспьютерах и RISC -процессорах даже частичный отказ одного из имеющихся типов вычислительных ресурсов (регистр общего назначения, стек команды или данных, арифметический сопроцессор плавающей запятой и т. п.) приводит либо к полной потере работоспособности, либо требует полной перекомпиляции программ. В последнем случае необходимы встроенные средства глубокой диагностики, задающие действующую конфигурацию вычислителя, и высокоскоростные трансляторы.
В таких условиях априорное создание различных версий загрузочных модулей программ оказывается малоэффективным, так как при многократном увеличении объемов памяти такой способ позволяет парировать только заранее запланированные отказы, что практически бесполезно в условиях активного противодействия противника, обладающего оружием направленной энергии.
С другой стороны, достаточно экономичные централизованные схемы холодного резервирования требуют разветвленной системы коммутации всех шин: управления, программирования, адресов и данных, и даже при наличии встроенных в каждый вычислитель средств диагностики могут парировать отказы только в (квази)реальном масштабе времени, так как введение подставленного холодного резерва в требуемую фазу вычислений сопряжено с определенными временными издержками, что в свою очередь приводит к приостановке вычислений во всем информационно зависимом коллективе вычислителей.
Граф информационной связности в параллельных (Б)ВС не остается постоянным, поэтому для приостановки вычислений требуется разветвленная система аппаратурных прерываний систолического типа, обеспечивающая произвольное динамическое разбиение всего коллектива вычислителей как минимум на два класса: активные и пассивные.
В результате в параллельных (Б)ВС на процессорах одной из традиционных архитектур парирование отказов в реальном времени в основном осуществляется по восходящей к Дж. фон Нейману схеме мажоритарного резервирования, которая в современных условиях строится на основе встроенных средств диагностики, уменьшающих, как показывает опыт, коэффициент резервирования с 3 до 2,2-2,5. Поэтому узлы многопроцессорных ВС, парирующих отказы в реальном времени и без потерь в результирующей информации, принято считать "идеальными" вычислителями, в которых проблема обнаружения и парирования отказов полностью локализована и не сказывается как на работе неисправного узла, так и на работе информационно связанных с ним узлов. Однако количество парируемых по этим схемам отказов ограничено величинами 2-3, что на 1-2 порядка ниже размеров карт отказов, которые могут возникнуть в результате активного противодействия с применением оружия направленной энергии.
Существующие современные технологии погружения задач в аппаратуру (Б)ВС, то есть нахождение представления задачи в булевом базисе, обеспечиваются отображением функций пользователя либо через конструкции языков низкого уровня ( ЦПОС -, RISC -, CISC -технологии), либо прямым отображением на кремниевые структуры (кремниевая компиляция, технология программируемых логических интегральных схем ( ПЛИС -технология)). В силу этого в ЦПОС -, RISC -, CISC -технологиях
конструктивно неделимой единицей проекта в диагностической плоскости фактически является отдельный процессор.
Бит-процессорная технология является практически единственной, где неделимой единицей проекта в диагностической плоскости является не всегда доступный с периферии СБИС бит-процессор с наиболее простой архитектурой, на поддержку которой уходит 200-300 вентилей.
С позиций выбора методов и средств обеспечения живучести субпроцессоров МКМД-бит-потоковая вычислительная технология обладает следующими особенностями:
- высокая структурно-функциональная гибкость, реализуемая на микропрограммном уровне управления, доступна разработчику любого уровня иерархии (Б)ВС;
- массовый ( \[ 10^{3}-10^{5} \] ) векторно-конвейерный параллелизм по ассоциативно взаимодействующим потокам команд и данных позволяет управлять вычислительными ресурсами в темпе реального времени, то есть непосредственно во время вычислений;
- простота процессорного элемента обеспечивает его проектную и диагностическую "прозрачность", что в сочетании с высоким уровнем топологической мультипликации (102-103 ячеек) позволяет достичь наиболее высоких уровней интеграции в сверх-, ультра-БИС и на целой пластине, не выдвигая завышенных требований к "интеллектуальным" и технологическим компонентам САПР.
Методологическое сходство данной технологии с зарубежными преимущественно ОКМД-бит-потоковыми технологиями на основе систолических СБИС [70, 142- 144, 277, 278] состоит в следующем. Проектирование СБИС ведется "сверху-вниз" во всех трех плоскостях: структурно-функциональной (в схеме рис. 3.5 речь идет о задачах векторно-матричной обработки), программно-аппаратной и диагностической. Оно нацелено на создание архитектур, адекватных ( базовым ) алгоритмам обработки, и на самых ранних этапах спецификации всей системы учитывает возможности и ограничения микроэлектронной технологии их изготовления. В современных условиях основная сфера использования МКМД-бит-потоковых технологий - это цифровая обработка сигналов, изображений и потоков данных режима реального времени, и в ней доминируют методы и алгоритмы линейной алгебры. Проектирование субпроцессоров ведется итеративно "сверху-вниз" и "снизу-вверх", нацелено на комплексное использование (полу)заказных и программируемых СБИС и учитывает специфику организации вычислений в каждой из них.
В зарубежных (Б)ВС в этой предметной области доминируют ОКМД-технологии, которые являются более простыми с точки зрения организации вычислений и инструментальных средств поддержки проектирования. Индустриальный уровень программно-аппаратных средств поддержки фун-
даментальных и прикладных исследований [279], а также успехи кремниевой компиляции при "бездефектном" проектировании и изготовлении зарубежных ОКМД-бит-потоковых матричных СБИС [98, 99, 135] предопределяют разницу в целях, задачах, критериях эффективности, распределении задач между этапами проектирования в этих технологиях. В частности, зарубежные исследователи свои усилия в основном сконцентрировали:
- на синтезе алгоритмически ориентированных систолических структур под конкретные задачи цифровой обработки сигналов и изображений реального времени [70, 76, 280],
- на методах отображения алгоритмов цифровой обработки сигналов и изображений реального времени на систолические структуры [70, 145, 146], что предполагает их (полу)заказное исполнение.
Поэтому в этих исследованиях реконфигурация структур и функций матриц, как правило, учитывает либо потребности узкого круга задач [70], либо потребности самовосстановления их работоспособности [147, 237, 281]. Данное положение подтверждается тем, что в репрограммируемом варианте выпущены единичные типы систолических бит-матриц [144, 148].
В прикладном аспекте основная стратегическая установка рассматриваемого варианта МКМД-бит-потоковой технологии состоит в том, чтобы минимумом комплектующих репрограммируемых матричных СБИС обеспечить решение как можно более широкого круга задач цифровой обработки сигналов и изображений реального времени. При этом инструментальные платформы такой технологии должны обеспечить эффективное отображение заданий пользователя на микропрограммный уровень организации вычислений, что можно выполнить в два этапа, на первом из которых синтезируются проблемно-ориентированные бит-матричные СБИС, учитывающие специфику решаемых задач, а на втором отображаются алгоритмы решения этих задач на конкретные бит-процессорные вычислительные структуры.
В теоретическом плане такая установка требует решения следующих проблем в сверхбольшом коллективе МКМД-бит-потоковых вычислителей:
- поиск эффективного распределения структурно-функционального полиморфизма на всех уровнях организации вычислений, начиная с бит-процессорного и заканчивая проблемно- или алгоритмически ориентированными субпроцессорами;
- поиск эффективного распределения задач и динамики управления на всех уровнях организации вычислений;
- обеспечение баланса в распределении аппаратных затрат между объектом и средствами управления на всех уровнях организации вычислений;
- обеспечение баланса в распределении аппаратных затрат между операционным ресурсом, коммутационным ресурсом и памятью на всех уровнях организации вычислений.
Стратегия проектирования и использования рассматриваемого варианта МКМД-бит-потоковой технологии исходит:
- из гарантированной возможности распараллеливания вычислений арифметико-логических, адресных, интерфейсных и управляющих функций, что апробировано в отечественных бортовых цифровых вычислительных машинах (БЦВМ) [282- 288];
- из максимального использования МКМД-бит-потокового конвейера, в котором ОКМД-фактор векторизации потоков данных играет вспомогательную роль, обеспечивая не столько распараллеливание вычислений, сколько согласование темпов поступления и обработки данных (см. раздел 1.5 курса "Задачи и модели вычислительных наноструктур");
- из высокой индивидуальной структурно-функциональной гибкости каждого бит-процессора, что, с одной стороны, обеспечивает алгоритмически ориентированную аппаратную эмуляцию широкого круга задач, а с другой стороны, обеспечивает минимизацию системных издержек за счет реализации спектра архитектур субпроцессоров;
- из совместного использования репрограммируемых и (П)ПЗУ-программируемых МКМД-бит-потоковых матричных СБИС, первые из которых обеспечивают высокую адаптивность аппаратуры к задачам, решаемым в режиме разделения времени, и открытость (Б)ВС на "время жизни" ЛА, а вторые снижают массо-габариты и потребляемую мощность дежурных и/или интенсивно используемых специализированных функциональных блоков (Б)ВС;
- из упрощенных методов структуризации алгоритмов и программ за счет снятия всех конфликтов в любом графе их представления за счет аппаратной реализации всех его активных узлов и ребер.
Преимущества такой стратегии проектирования и использования МКМД-бит-потоковой технологии проще всего показать, опираясь на хорошо известную схему Горнера рекурсивного вычисления полинома \[ k \] -й степени рис. 3.6-а:
| Шаг рекурсии | Операция |
|---|---|
| 1 | \[ F_1=F_{0}x+a_{k-1} \] . |
| 2 | \[ F_{2}=F_{l}x+a_{k-2} \] |
| … | ……………… |
| \[ k-l \] | \[ F_{k-1}=F_{k-2}*+a_1 \] |
| \[ k \] | \[ F_{k}=F_{k-1}x+a_0 \] |
где \[ F_0 = a_k \] , а вычисляемый полином имеет вид
\[ P_k(x) = \sum\limits_i{x^ia_i}, \,i=\overline{1,k} \]
Схема рис. 3.6-а не оговаривает способа поступления "внешних" переменных \[ х \] и \[ а_{i} \] , первая из которых обычно считается "быстро" изменяющейся функцией целочисленного времени \[ х = х(Т) \] , а вторая может "медленно" изменяться в адаптивных алгоритмах \[ а_{i} = а_{i}(Т_{0}) \] , где \[ Т_{0} \] - интервал постоянства \[ \{а_{i}\} \] .
Конвейерная схема распространения "промежуточных" переменных \[ \{F_{i}\} \] рис. 3.6-б минимизирует время выполнения инструкции в каждом операционном модуле, но требует тактируемых синхроимпульсами (СИ) элементов задержки ( D ) и в микроэлектронном исполнении неудобна тем, что:
- ограничивает "глубину" ( \[ k \] ) одномерного конвейера из-за параллельного соединения \[ k \] -входов;
- предполагает хранение коэффициентов \[ \{а_{i}\} \] в локальных ОЗУ малого объема;
- требует отдельной адресной шины ввода этих коэффициентов, которая по площади занимает больше места, чем само ОЗУ;
- требует подготовительного цикла обновления \[ \{а_{i}\} \] в случае использования адаптивных алгоритмов.
Если считать независимыми скорости распространения потоков данных \[ Х_{i}(T) \] и \[ А_{j}(Т) \] и абстрагироваться от смысла и сложности инструкции, выполняемой каждым операционным модулем, то схема Горнера трансформируется в классическую линейную систолическую структуру (рис. 3.6-в). В этой схеме пары "внешних" операндов \[ Х_{i} \] и \[ А_{j} \] создают произвольные наборы комбинаций с "внутренними" переменными \[ F_{i} \] за счет вариаций задержек \[ \{D_{1}, D_{2}, D_{3}\} \] .